News Archive - 2011
Friday, 14 October 2011
DataShop 5.1 released - Redesigned KC Models page, cross validation, citations, and an important change to the transaction format
Redesigned KC Models page
We redesigned the KC Models page as a table to make it easier to compare models. You can sort the models by any of the statistics in the table using the combobox at the top of the page. By default, KC models are now sorted by AIC instead of BIC (lowest to highest, or best fit with fewest parameters to worst fit with additional parameters) and then by model name. The sort order chosen also affects the order of models in the KC Models combobox seen in the navigation area of various reports in DataShop.
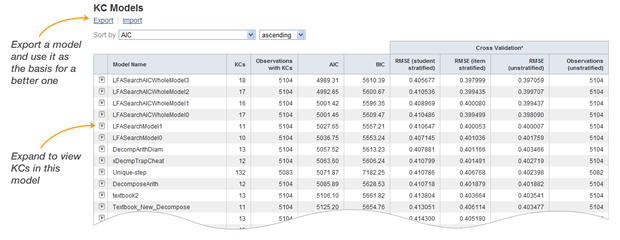
Cross validation
Cross validation statistics for KC models have been expanded to include two new methods of cross validation: student stratified and item stratified. Cross validation is a technique for assessing how well the results of a statistical model (in this case, AFM for a particular KC model) will generalize to an independent dataset from the same tutor. It's reported as root mean squared error (RMSE). Lower values of RMSE indicate a better fit between the model's predictions and the observed data. More information on these new statistics is available on the Model Values help page.
Tell other researchers how to cite your dataset
We've added two new fields to the Dataset Info page: Acknowledgment for Secondary Analysis and Preferred Citation for Secondary Analysis. Using these fields, you can display a citation and/or acknowledgement that others should use if they publish research based on your dataset. Once filled in, the citation/acknowledgement is shown in two other places: on a new subtab called Citation, and in a text file that is included with each export of the data.
Changes to the transaction format
We've added two columns to the transaction format, Problem View and Problem Start Time. Problem Start Time identifies when a problem is shown to a student. This information was missing from the tab-delimited transaction format even though it was possible to log using the XML version of the format. It's now possible to export a dataset that has problem-start information and re-import it without losing any data. Similarly, you can now import a new dataset in the tab-delimited format that describes when a problem is shown to a student. Problem View serves a complimentary purpose. It counts how many times the current problem has been encountered by the student. The addition of these columns fixes a long-standing limitation of the tab-delimited transaction format.
You will find updated definitions for Problem View, Problem Start Time, and Step Start time on the export help page.
Data changes
As part of the changes to the transaction format, we've made changes to how problem view, problem start time, and step start time are calculated. These changes will modify metrics for datasets that were created via the tab-delimited format (or, in rare cases, if logged in the XML format without problem start information). These datasets will change in the following ways:
- For the first step of the problem, the step start time is no longer indeterminate, so instead of seeing a dot (".") for these steps in the student-step table, you'll see a time value. The same applies for the step's duration.
- Because of how problem start times and problem views are calculated, it's possible for the "attempt at step" count (seen in the transaction table) to be different. This difference means that metrics for KC models such as as AIC and BIC may be slightly different.
Bug fixes
- Web Services: requesting both custom fields and specific columns for transactions now includes custom fields
- Web Services: updated user agreement to include public web applications as a restricted use
- Web Services: we now support requesting the transaction columns "problem view" and "problem start time"
- Web Services: column shifting is no longer present in the student-step export
Thursday, 21 July 2011
Interested in finding better KC models automatically!?
Ken Koedinger and Hui Cheng have developed a method for automatically applying the LFA search algorithm to any dataset with at least a couple existing KC models. LFA returns new KC models (aka cognitive models) that are usually better than any of the existing models.
This version of LFA model search is based on Hao Cen's LFA method (described in his dissertation), but it only requires some existing KC models to start its search for a better model—it does not require a researcher-generated matrix of difficulty factors by steps in the curriculum (a "P-matrix"). The better the existing KC models, however, the better the LFA model search results are likely to be.
If you are interested in finding better KC models, let us know and we will run the LFA model search on your data and attach the resulting KC models to your dataset. We will offer this service on a trial basis. Note that the LFA search can take days or weeks to run, depending on the size and complexity of the dataset.
A distinguishing feature of the LFA method is its semi-automatic model search process. Cen et al. formulated finding a better cognitive model as a combinatorial search problem. Given an existing KC model (a Q-matrix) and a combination of hypothesized factors or KCs from other existing KC models (all these factors are the P-matrix input), LFA search automatically incorporates those factors into models, and finds new models that researchers may wish to investigate further.
Tuesday, 28 June 2011
New demo videos from Phil Pavlik
In these short videos, CMU Systems Scientist Phil Pavlik shows how he exports data from his MySQL database, verifies the tab-delimited files with the DataShop import verify tool, and uses DataShop web services to programmaticaly retrieve data from DataShop.
You can view the videos from the AIED 2011 Tutorial page.
Thursday, 26 May 2011
Workshop: Importing your Data into PSLC DataShop
We are writing to invite you to our upcoming workshop: Importing your data into PSLC DataShop.
When: Tuesday, June 14, 2011, 9:30am-1:30pm (lunch will be provided)
Where: CMU, Gates-Hillman Center (GHC) 6115
During this interactive half-day event, you'll have the opportunity to learn how you to get your data into DataShop. You'll also hear a case study from CMU Systems Scientist Phil Pavlik on his experience of importing tutor data into DataShop.
Schedule
| 09:30am - 10:00am | DataShop Overview |
| 10:00am - 10:30am | The Data Model |
| 10:30am - 10:45am | Break |
| 10:45am - 11:45am | Importing Data (hands on) |
| 11:45am - 12:00pm | Exporting Data |
| 12:00pm - 12:30pm | Case Study - Phil Pavlik |
| 12:30pm - 1:30pm | Lunch and Discussion (optional) |
Be sure to bring a laptop so that you can participate in the hands-on portion. Also feel free to bring your own tutor data (in Excel or a tab delimited format) to get started or we will supply example data for the hands-on portion.
If you are interested in attending, please RSVP! If you know anyone who might be interested in this workshop, please tell them about it!
Friday, 6 May 2011
DataShop 5.0 released - improved import tool for tab-delimited files, bug fixes
Import tool for tab-delimited files
This release of DataShop concludes work improving the tool used to import tab-delimited text files into DataShop. With these improvements, loading large tab-delimited text files of transaction data is now possible. It's fast, too.
As part of this release, we have used the new import tool to load 6 datasets that we had been unable to load. These datasets range in size from 122,000 to 870,000 transactions.
Although we have improved the import tool for loading data, you should continue to use the import file verification tool to verify your files before sending them to us to load. We hope to improve this process in the future by allowing you to verify files and create datasets through the web application.
Bug fixes
This release includes a number of bug fixes. Some of the more critical bug fixes:
- Sample Selector preview table displays more quickly for large datasets
- AIC & BIC values are now consistent between loading a new KC Model and rerunning AFM from log conversion
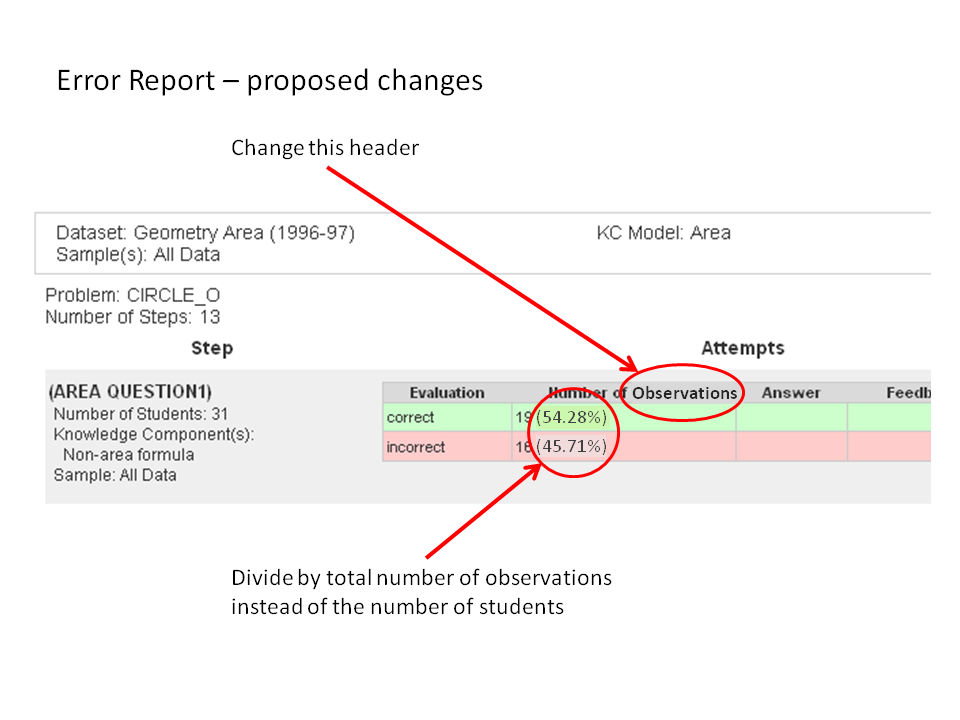
- Error Report: the corrects (and incorrects) were being divided by the Number of Students to get the percentage. This was a bug, because students can do a problem more than once. Here's an image describing the change.
- Student-Problem export did not include steps without KCs
- Dataset Info: URLs were making description field too wide. We now try to force URLs to wrap, and convert them to links so they're clickable.
- Dataset Info: We fixed a few line-break issues in the "Additional Notes" and "Description" fields, including one where line breaks were lost and sequences of space or line-break characters were condensed in IE7/8.
- Student-Step Export: KCs are now exported by default
- Student-Step Export: the preview table didn't load if a secondary KC model was selected
- Sample Selector: selecting 'Share this sample' when creating a new sample didn't share the sample
{kind=link}
Tuesday, 22 February 2011
Join the datashop-users email list
Want to stay up-to-date on DataShop news or send a message to the community of DataShop users and researchers? If so, consider subscribing to our low-volume email list.